concept progress files

intro
this page presents some ideas or describes the many stations during development circles for your consideration, for fun & beer and for projects that may raise up in the upcoming years.
having a content management system is not that new anymore. over the years some of the plenty grown cms stayed on the internet, some more vanished or will rotten on repositories for ever. building a management and rendering engine, which deliver criss-crossing data in the background or load-balancing the request transparently, was the main idea. after some use-cases, a initial upload service was to trivial to release, instead docking further functionalities onto it, was more interesting. building the key or frame-like parts for a system like that was more then just to customize the web-server. reading and manipulating the header-request of the http-connection with caching-features, as well as for the whole file-related part, was implemented later. having templates, when building the actual login and register form ready for any other place-holder is on the table right now.
unfortunately, the distributed machines are offline at the moment. bigger changes in the app made it local on the development computer and i decided to take the previous version offline. the route is also changed on the dns-server and served from a vhost in some webspace.
the hardware-park is also being upgraded meanwhile, so the happy-hour of restoring the settings will hopefully come soon :/s tatic and dynamic content and request is separately routed in this design, two use-case examples below reducing the need for remote procedure calls, is the main focus. the active parts during real-user-transactions are covered as server-based-computing context. as the service is running on tomcat and nginx, the time for a roundtrip could be reduced to single numbers of milliseconds.
frontend / technical pagedesign
the thin relief from the welcome page, with some jquery plugins for picture and navigational capabilities and piecemaker als picture library and videoplayer. i would call that picture clean and the design lean, but we need to see, how it grows over the time and how it will work, when its generated.
within the firefox that powerful thing is sleeping in the most cases. sometimes, the z-position of layered elements counts for their visibility and behaviour. as i use jquery in some places, i need to figure out, how they act and how they want to be treaten. working with gwt had different issues for the same problem on the programmatic regulated base. working with pure java script is sometime like a blind flight along a cost with just fog to see.
here one can see the layered and used container, to build a page like that. i hope it stays that way, then i would use it as template for any other storage or cloud visitor. now we got 2-3-4 layers wrapped together, working inside a mobilephone or tablet app could result a depth to 5, 6 or 7 and each of them wants to be feeded. the actual plain design of that static page is somehow used, but sorted or a bit virgin to me.
backend / datamodell
during the work with the datamodel, i painted some ideas down, with wishes that i had from the past or some ideas for the future, but it was just a try, to start sorting things out. the dilemma was, that the final and working structure wasnt clear in 2011, as default modelling tools and normalization is obsolete somehow in these days and the kings road is still out of sight.
the usage of hibernate or jpa annotated classes is still not fitting the need to have the same class/object in the gui under java script. in gwt, just a white-list is provide to be compiled to javascript from java. annotations are not feasible at the moment and it dosnt looks like the way, that this behaviour is implemented into that framework. so one need something other, like datanucleus, that reworks the classes on the byte-level, but with annotations as well and therefore not usable within the gwt-context.
ideas, to bind classes with xml-files, containing the mapping and the configuration settings for generics and reflections are already on the market, but maintaining the files on two tiers or three is not funny at all. one can generate such classes, out of a template, but taking care for many data-model-files ( pojo ) takes a lot of energy of the process.
thats why i took much time to figure out a nice way, that is handleable during the development. i estimate something like 50-70 objects or classes or entities or tables needed, from the actual viewpoint, but in some enviroments, a couple of hundret tables are common in enterprise apps. reworking the datamodel should be nice and easy, and that preparations are made, even if the garbage-collector is maybe stressed. another way is to use plain jason-objects, but that has a lot of dis-advantages in form of making the type of object safe, validation and objectmapping, de- and serializatioen is also to solve, makes it not sexier, then other techniques.
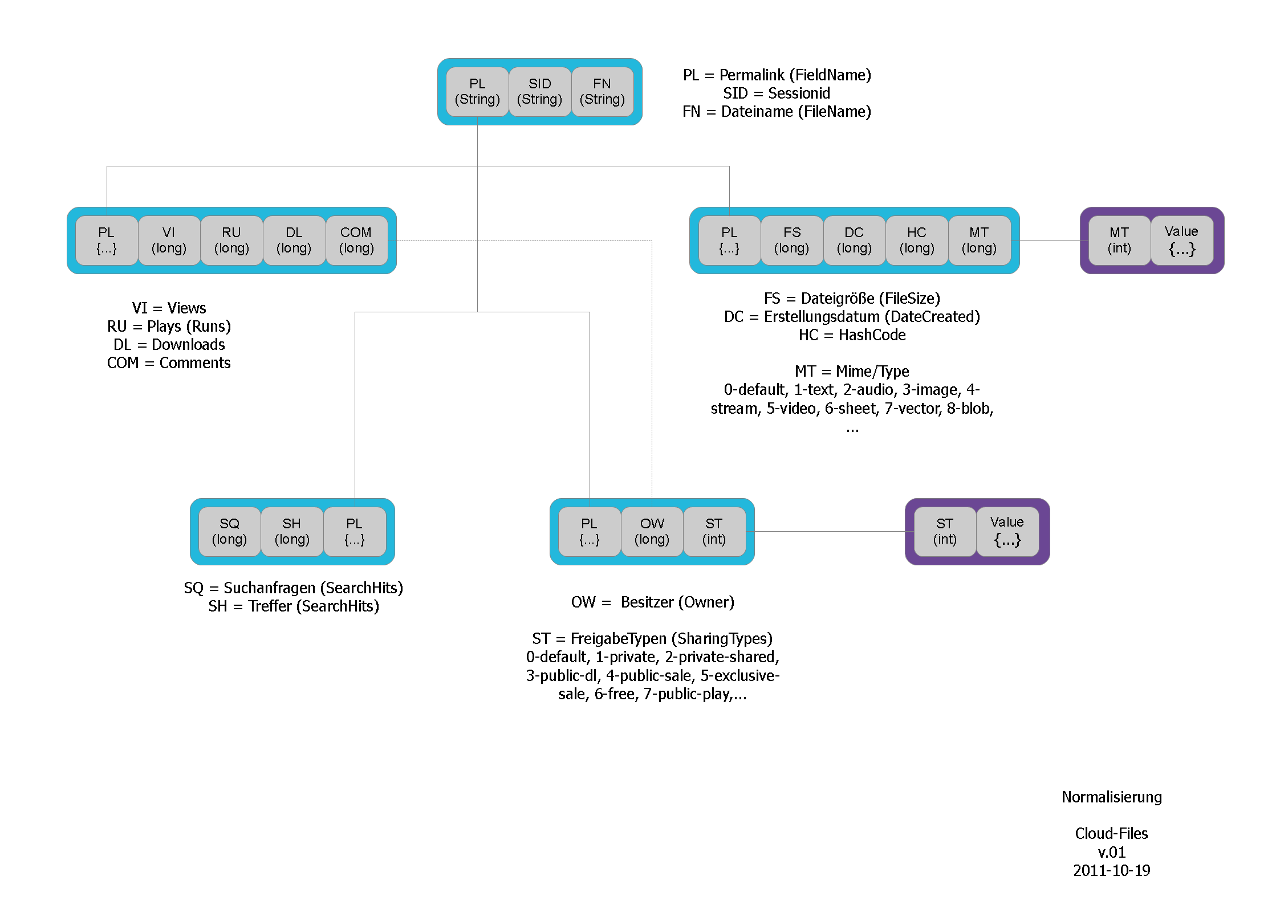
during the work with the data-model, i painted some ideas down, but i didnt felt well with that puzzle-pieces, i made. seeing professional design and build tools during some projects showed the urgency for that level of iterative development, and as if data-conversion is easy for a hadoop-based system, i went the way on test-driven-development without diving so much deeper into the data-design. iam simply to lazy to prepare a detailed plan with office tools or from the open-source world, i have something like code-generation, re-factoring and visioning in my mind.
the example above is about the usecase and the polymorph state of data, exchanged with the client within a browser gui, the managing server, in this case a tomcat should be more then enough, and the distributed file-system from hadoop. sharing the very same classes on that three layers was my conclusion for a cheap work. as i checked the performance during the evaluation of different datatypes and protocols, i had an eye on the time and resources consumed within that processes. the actual working copy of that model is even to me a thing i can think or work with, but painting it down, with lots of other classes that needs to fit to that model, is kind of thing. i tried a couple of ideas to solve that task, but i still working and rewriting it, testing more and more cases, takes some time.
sharing the data between the hadoop distributed file system ( hdfs ), a web-server based on java and a client, able to understand the main functionality the same way shows some nice effects, usually named as synergy. it took several stages the past years to have all the tools needed, to build a whole system with a single person. knowing some fast interpreting or compiled languages like perl, python or php is common. dealing with dynamic requests between the file-storage on windows or linux, is also nothing new. talking to a database in different query dialects is not funny at all. furthermore, uncountable manufacturer and market player diversify that market to a fragmentation-level with brain-aches for the one, who want to plumb all that stuff together. its maybe quick and sometimes dirty, but switching the context during real-world-development sucks a lot. serving the demanding client with data or rendering complete results for the browser ( static ) is the third part to handle.
#

the object type, used on the gwt<->rpc is very similar to the object, which is needed to fill a form or a table table-storage. as some data has some more dimensions, then a simple key-value-pairs and moving, copying the data inside the system and the request-chain wastes so much that i will try to come with that way far enough, to enjoy it a bit. clustering is a bit like grouping something, similarities are essential in that constellation, that bunch of power can then work on the same issues or be more efficient, then monolithic installations.
the behaviour of software differs sometimes on small or bigger installations. the combination of several influences on attributes is the cluster the way to have safety buffers on the amount of copies and clones. therefore its urgent, that the 3 different data-center are located outside the hazardous area of another. the infrastrakture is then so close to an actual cdn-company but the market should be big enough for such small ideas.
cluster / cloud
the synonym cluster is adopted with similar issues like cloud or grid-computing. the collaboration of soft- and hardware is so huge, that some company shares computer and some takes many of them. administrating that thing was a very specialiced corner of employment, that they had a league, the top500 org. meanwhile, the lasting increases of power and influence on the computing-sector did not changed or invented much in the past two decades, but with networks, so large that a single data-center could not satisfy their needs with one site. the amount of data is more, then the biggest computer can take, so many of average or oldies were take, to put them together in different constellations.
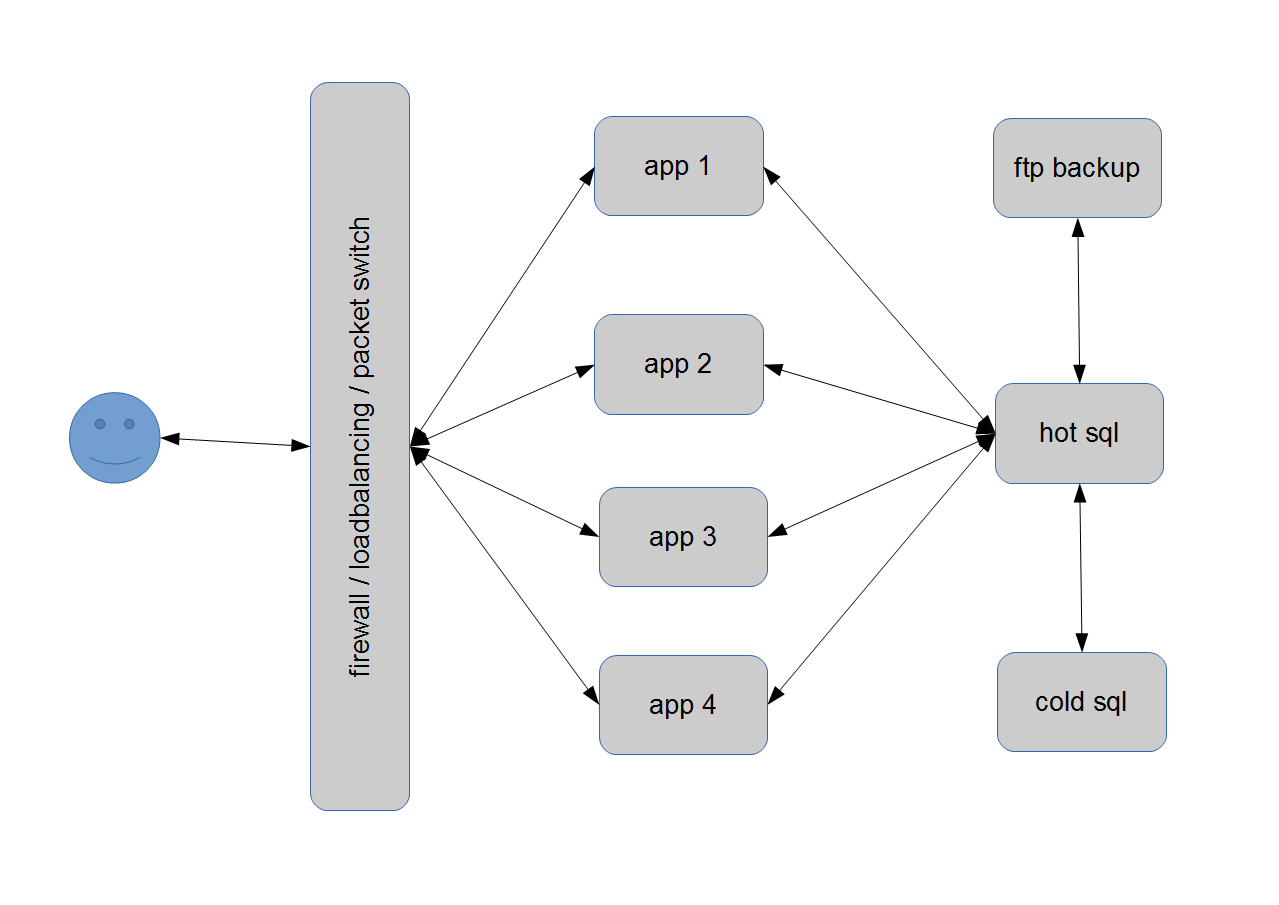
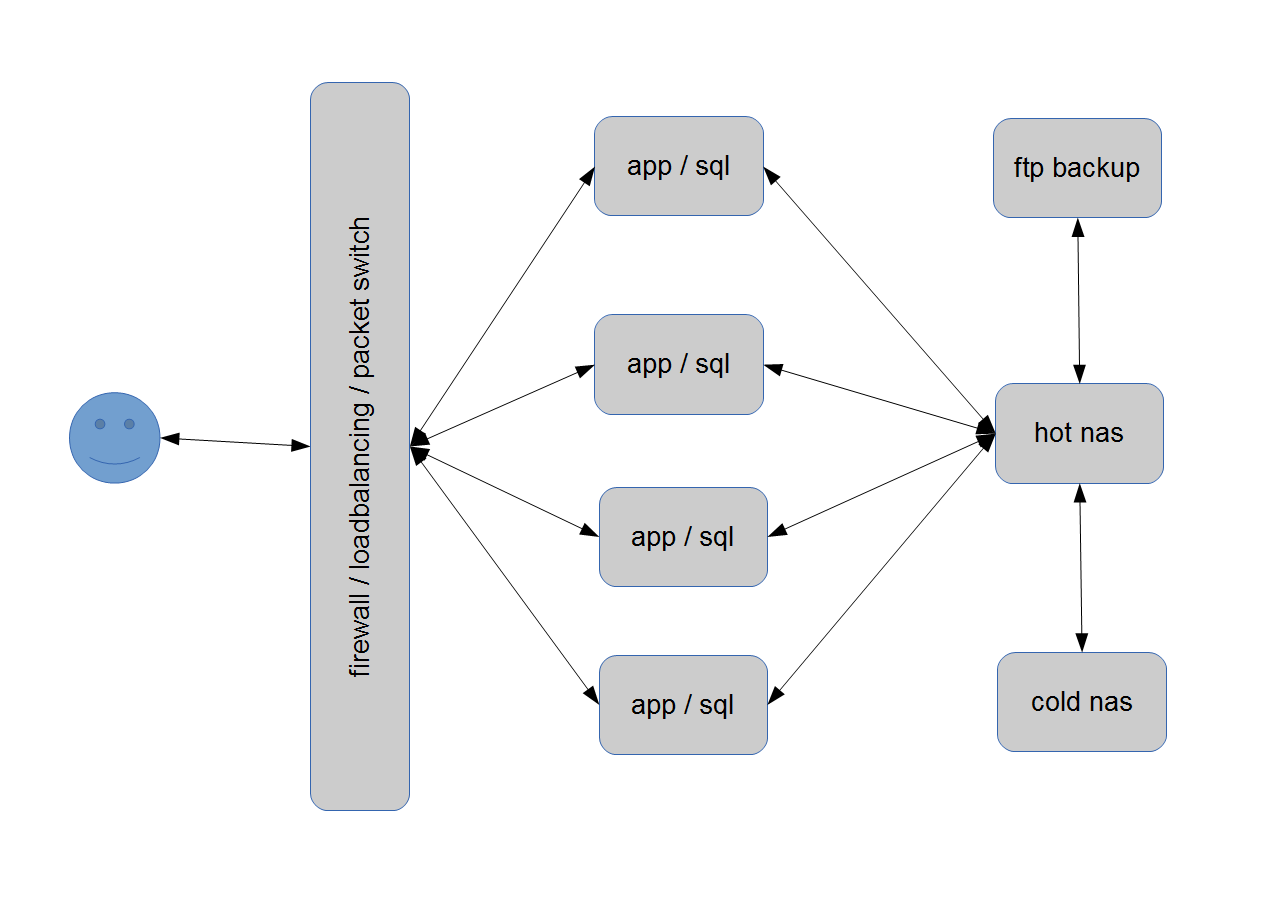
left side is the conventional scaled method, the right model plays the nas-card. historically, as it is common to say so, the conventional setup were skaled out from a dedicated app-server which get the heavy load and a dedicated data-base-server to care for the data on a single place, without delta-loads. the app-server were made redundant and secondary able to capture the request from outside, 4 machines will saturate a medium database-server, so the quadruplet power is possible. the trust lays here on the db-server, which is backed with the day-lie dumps.
another way to use six servers, the seventh is still needed for file-based-backups, is, to put the database on each appserver and this clones together can work on the same physical database-file, which is connected via networked attached storage ( nas ). that nas needs a copy as well and again, we want a raw copy of the essential file, on machine number 7.
both designs are still common in our time, the usage is sometimes similar or different as described. these amount of servers, six peaces is wideley taken to maximise the systems power by outsourcing the problem to another clone. in the most cases a fire-walled switch routes the request to the least working server, basically with the round-robin-method, on specialized machines more complex with a score of each member within the installation. both of that designs dos not scale any bigger, by using twice the amount of machines, the backup is just realized. that limits large-scale-application by the meaning of a single service. sharing a problem on many machines went on-line with stuff like soap or restful or proprietary protocols from big companies. a plenty big farm of machines were orchestrated by a master or root-node, that over-handed the client to a free or spare machine in the park. that design grows to something like 40-80 cores/machines, but playing with hundreds or thousands of boxes, was a domain of the supercomputer and mainframe vendors with extra ordinary prices and the portfolio for such threads.
starting with a loose coupled group of servers on a switch or a hub is the cheapest clusters available. dividing the problem into smaller parts, is a way to drill down bigger parts. that parallelism has an efficiency in the area of 60-80% on hand-chopped-woods. non optimized systems are far below, which makes no sense to put them on a cluster. that is the best for a single machine, can scale the work over the armada. different protocols were in the focus of architects, but much more then synchronous/asynchronous message, event or time-driven, but mostly limited to the management-software of that cluster, nowadays that thing is called 'supervisor' or so.
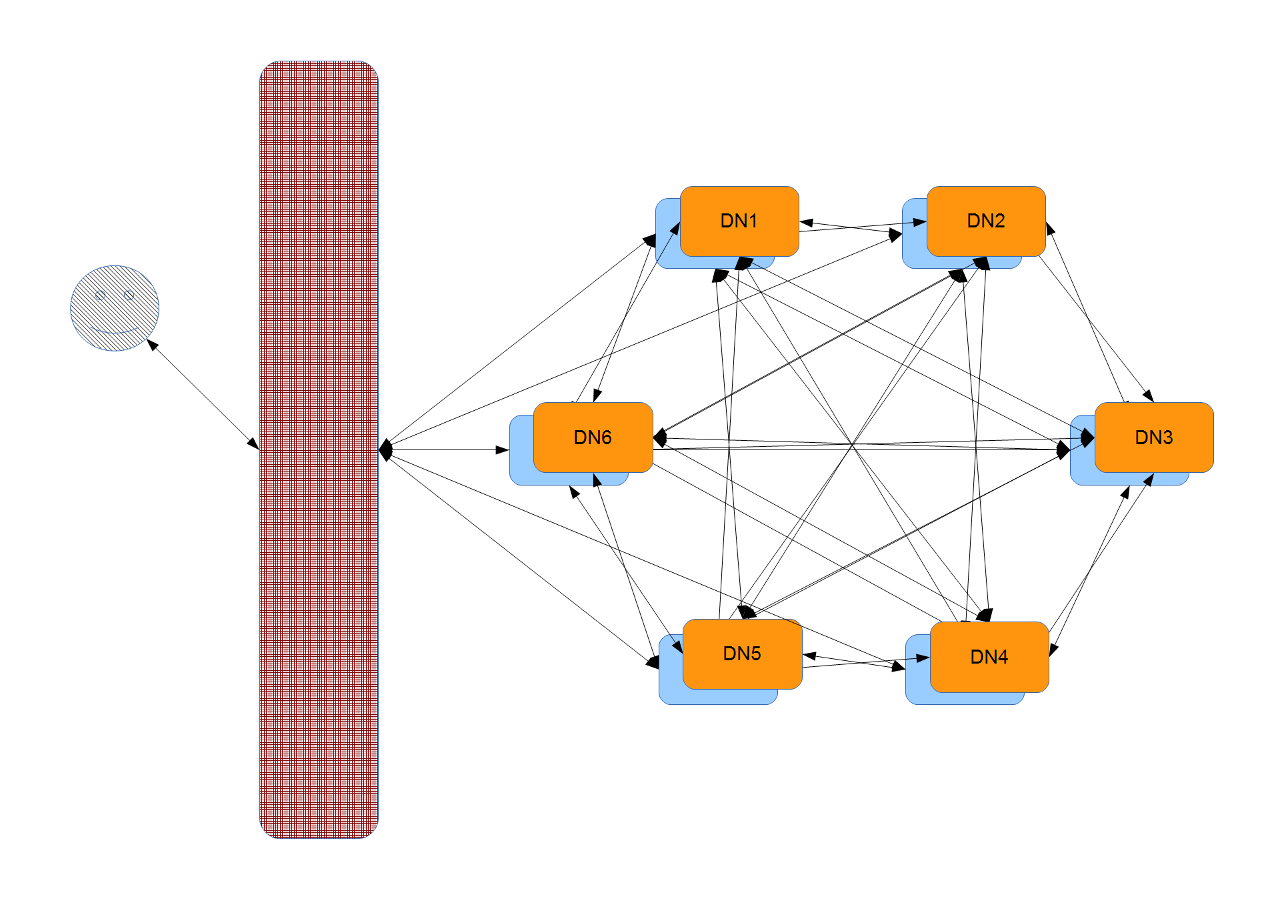
if one is asked, how a server is connected to the real world, it leads mostly to a switch with one or two cabels connected. anyhow if the line-speed is 1 or 10 gibit/s the six machines are wired with two or maybe four cat-x cables, connected with a star-scheme with the switch in the middle. but a switch is more, that cross-bar can connect each member with any other. pumping the logical bandwidth inside that network is lost, when the requesting machine exceeds the line-speed of the local network. on a cluster, all other machines can do the same and with the robust and simple architecture of hadoop, the data is shared between the members. if the cluster reaches the number of replication, lets says replication plus one, some scale effects take place in that system, that not many people noticed since yet, but the accumulated bandwidth outperforms numbers of the enterprise storage arrays for a lot more in cash. in fact, the san has a realtime bandwidth with 4 or 8 gibit/s, they are bundled and multiplexed up to some dozen, but the real usable capacity of that nas is reached during permanent growth. the example above gives a raw bandwidth of two port for each machine, resulting 12 gibit/s theoretically. affordable nas with two fibrechannel each 4 gibit/s has a bit less than that number, but think about ssd-performances, on some point one will reach to much accumulation of data and sharing it with a mirror will be unacceptable or slightly not possible on some point.
above the example with it six server again, each could delivers content with a simplified http-server to the outer world. the client from the internet or outside is randomly arrived on one of that machines and wants a website and music and later on a small film as finisher. the blue part is something like a apache, nginx or other slim web-server with routing capabilities could be used. the web-server redirects the request to its under-laying tomcat-server and this one organizes the data via web-service for example. so far so good, that has be done before. in fact, each server is now equal to the other and instead of 4 workers, 6 can now go on that duty to serve the web concurrently.
on a distributed file-system, the file is served somewhere in the system, so asking and requesting it on the network could leads among each member or mastering it with a directory- / index-services results bottlenecks bottlenecks and is not really scaling on large or extra large data sets. moving terabyte over gigabit ethernet is not funny and is far away from intermediate or near-time responses. the observed scale effects makes a cluster with ten machines comparable in price and performance with far more advantages the just ten fans in the corner. the traffic stays inside the cluster, but from outside, you will never get the information, if your file is on machine 1 or 5. one could report such changes, but that information is not making any effort on the case.
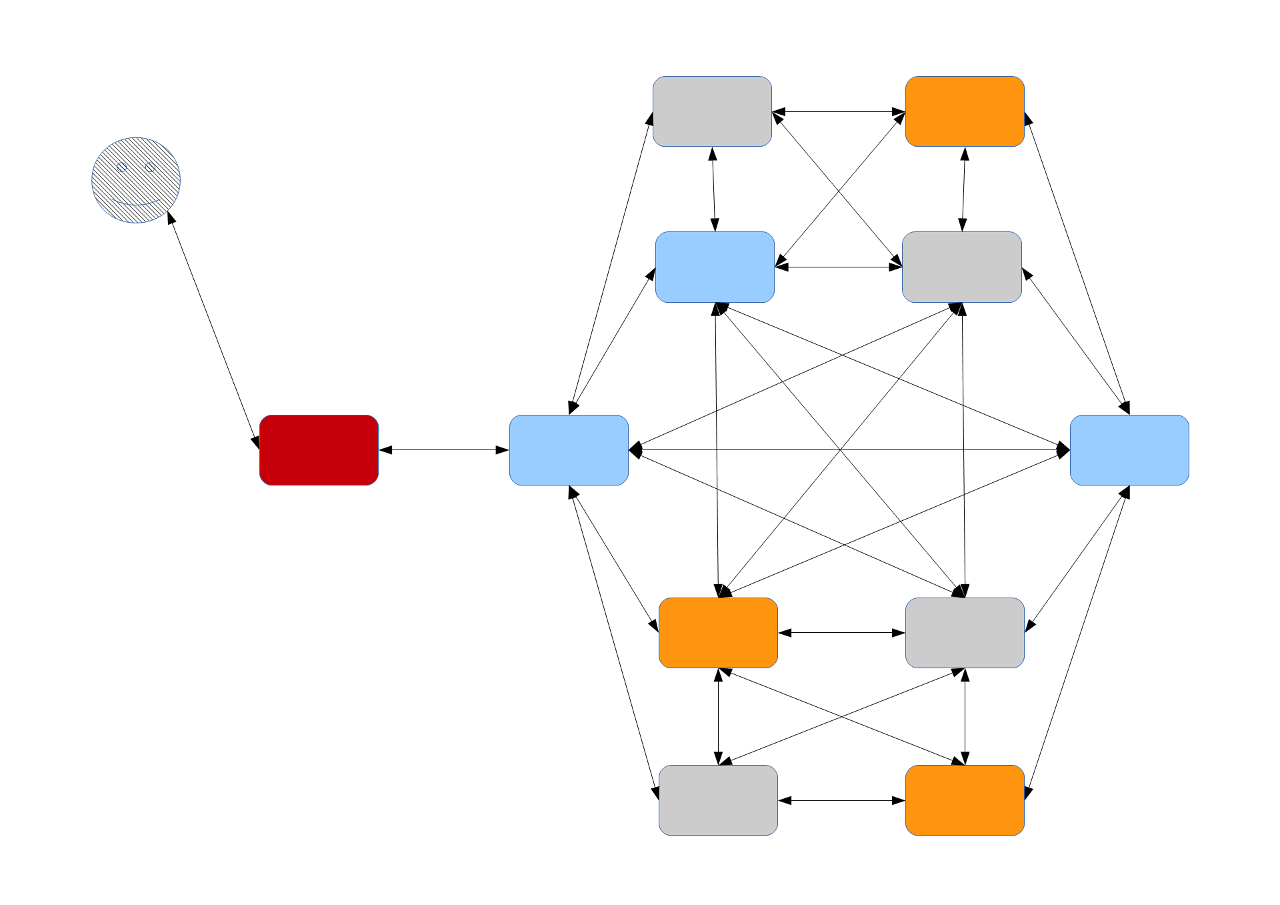
as configuration example, a ten machine cluster will be enough to understand the myths, that lays on the topic. the red icon is the firewall again, the load-balancing part choose d the blue in front of it, which is in duty with two other machines to bring the minimum safety to the system. as each server could speak to any other machine, over the crossbar of the switch, the painted connections just shows some more cabels used, as 8/12/16 gibit/s could provide beside the financial aspects. anyhow the server does not have the files from the wish-list and request it across the cluster and three nodes went active to send the snippets over. depending on the size, if a threshold is reached, the file is not collected and build on the server, it is straight streamed to the requester.in that constellation, four machines are not used and could be taken for analytical jobs or to deliver material to a complete different customer, without knowing the other participator directly. the larger the cluster grows, the more information could be squeezed out of the vast amount of data, collected.
understanding the basic mechanics of the system, writing own jobs or asking queries gives one the idea, that classical methods to stress the data are simply not enough for large scale clusters with some thousand machines and times more cores bring fantastical resources for data-driven-research. integrating basic statistical functions above the rule of three takes advantage of massive parallelism and heavy rates on throughput and space. with some essential gear transmissions between the lines, the traction of resulting solutions are ready to deploy.
mechanics
the gear-wheels that bring this or that result to life, got some very tough parts and some very cheesy. when to synchroize, block or streaming the data
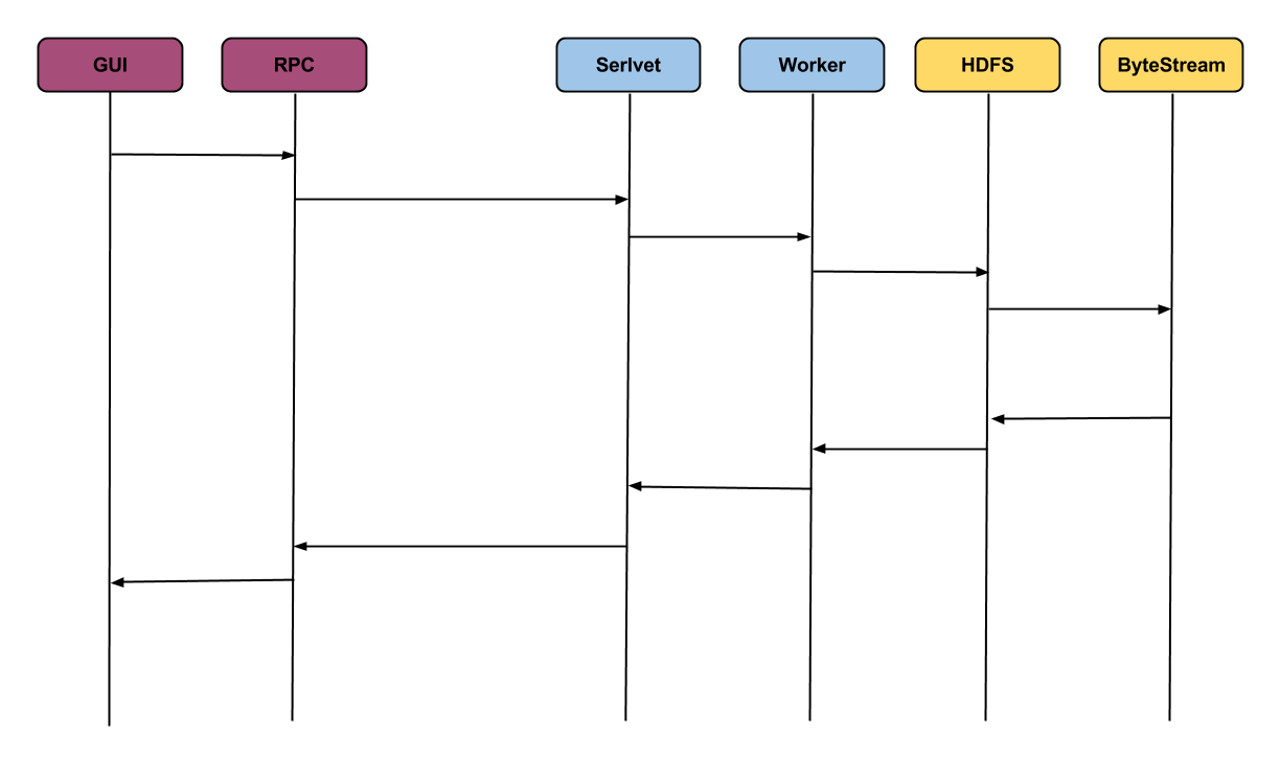
what runs on one machine, will probability run on others as well. hadoop is the hard framework, that kicks in the whole infrastructure with everything in java, where u needed a whole team few years ago to keep it running. the apache community established a good tool-set of necessary basics, that several design patterns are already shows its success in several different other projects. mixing web-related knowledge with pure enterprise related topics engage people to mix the market with affordable material.
the choice to walk that way is somehow mechanic, as the existing different dogma nor the different use-case-environments were in the rush to wilder in others districts. moores law, 20 years of windows nt, pure java projects in such software, the market went adult over the years, to jump bag to the curious points in life to learn something new, which was so far away from the traditional market, that single-threaded salami-tactic was so successful on cheap machines, that even the big tiers of storage and database vendors shifted in the direction of that non-monolithic designs.
content delivery networks
scope
the different data-center are initialy located, in three locations across germany. the stage for plain customer is in berlin for example, the 2nd largest crossing-point in germany. there is loadbalancing and one instance located. the next engine stays in the area around jena in south-east germany. the thirs location is not far from cologne and munich connected, makes it possible to serve incoming request with the shortest route or the cheapest passage to its data.
commercial or private customers can choose between pre-pushed content to hotspoted accesspoints or lazy-load driven station with the given and tested configuration, to deliver as quickly on demand. the design brings a lot of potential to extend the services in different direction, but the frame and core-logik must be created to think that way.
delivering more then the requested file in advance need some infrastructure and push services, in the past. with a distributed filesystem across countries and continents, one could had all files from everywhere with backbone speed. delivering content is the main mean of serving media-files to customers, which decided to do so. static content, everything without lookup could be delivered, without knowing the business better as them. that outsourcing of workload differs between the industrie and the customer. the company wants to present itself at its best, triggering the buyer to leave something lately. attention, clicks or even money. quick reaction, backups and the scale for many users needs to scale as well.
with core features and a base stock of customers, the cdn business looks like reachable from the technical point of view. learning and growing the machine park will lead itself to other, bigger boxes. shifting unseen data between the location needs to be calculated and observed over a long period.that experience will grow over the time, before one seriously want to call that construct then a cdn.
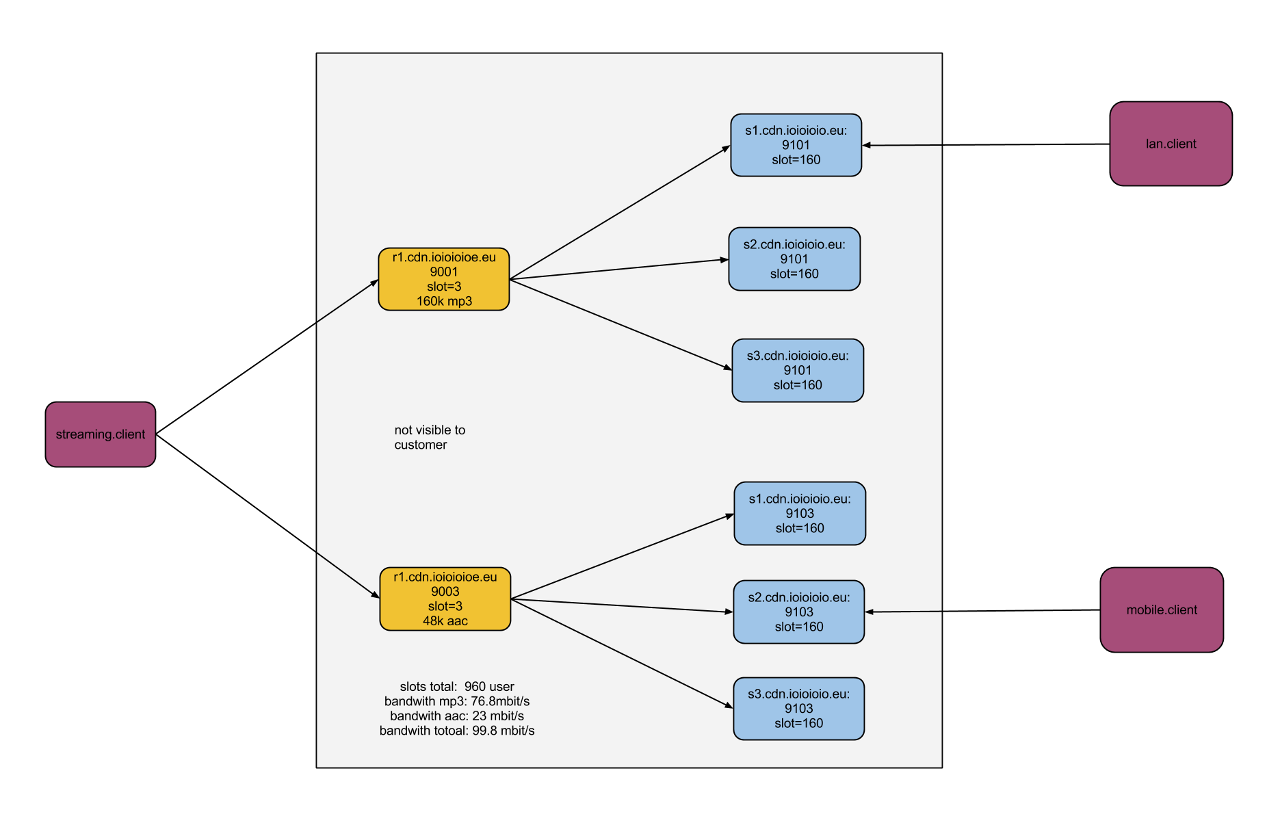
the example above shows some material about radio-streaming within the internet. alternative music-sources with some ten-thousend stations out there and these kind of content, the stream is requested, a linear need of bandwidth must be handled slightly different then time-uncritical communication systems. anyhow the customer comes thru the firewall to one of the blue coloured servers, a phalanx of services or even servers, with the capacity to bring the contracted hundret mbit/s at least or even more. the diagram shows a composite calculation to serve 1000 user on a pizza-box of hardware.
2014 (c) ioioioio.eu